유튜브에 'deep learning' 에 관해 검색을 해보았더니 어떤 꿀강좌들이 나타났다.
다름아닌 MIT에서 제공하는 'Foundations of Deep Learning' 이라는 계절학기 코스로 MOOC(한국에서도 요즘 제공하는 온라인 무료 대학강의)의 하나라고 볼 수 있겠다.
친절하게도 이 과정의 모든 lecture들이 재생목록으로 하나되어 올라와 있었고 마침 deep learning을 시작하려하는 나로서는 주저하지 않고 수강을 시작하였다.
아래는 그 중 첫 번째 lecture를 정리겸 요약한 것이다.
코스 이름 : MIT - Foundations of Deep Learning
MIT - 딥러닝의 기본
Lecture 1: Introduction to Deep Learning
강의 1: 딥러닝 소개
The perceptron
퍼셉트론

퍼셉트론은 그 유명한 신경망(neural network)의 기본 단위이다.
위의 동영상에서 가져온 그림과 같은 구조로 이루어져 있는데, 입력값에 두 번의 계산을 거쳐 출력값이 결정된다.
왼편을 보면 $x_1$, $x_2$, $x_m$과 같은 여러 변수들이 있다. - 머신러닝에선 feature라고도 하는데, 각각의 변수는 하나의 feature를 나타내며, 이 feature는 어떤 특정한 데이터 값의 한 종류(예를 들어 '키'라던지, '몸무게' 라던지, 하나의 독립된 변수)를 나타낸다.
머신러닝에서 기본적으로 쓰이는 알고리즘이 나중에 나오는 '경사 하강' 이라는 것이다.
경사 하강법에서 우리가 알아내고자 하는 것, 아니 머신러닝에서 근본적으로 학습하여 알아내고자 하는 것이 바로 위 그림의 $w_0$, $w_1$, $w_2$와 같은 '가중치(weight)'이다.
아무튼 퍼셉트론에서는 어떤 w값들을 $x_n$에 곱하여(내적) $w_0$라는 편향(bias)을 적용한다. 그 뒤에 보이는 것이 다음 스텝으로 비선형 함수를 적용하는 것이다. 비선형 함수란 sigmoid 함수나 reLU와 같은 함수인데, y와 x의 방정식을 1차가 아닌 다차로 만들 수 있게 된다. 그 후 나오는 값은 비선형 함수에 의해 0부터 1사이의 하나의 값으로 나와 final output이 된다.
* 참고: sigmoid 함수의 텐서플로 코드는 : tf.math.sigmoid(z)
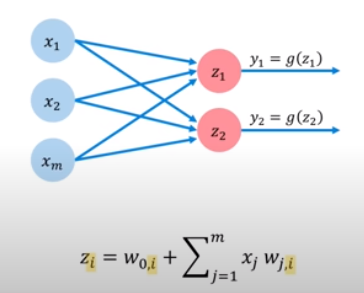
* Multi Output Perceptron: 위와 같은 퍼셉트론에 weight들을 다르게 해서 또 다른 output을 만들면 위와 같은 다중 출력 퍼셉트론, multi output perceptron이 된다.
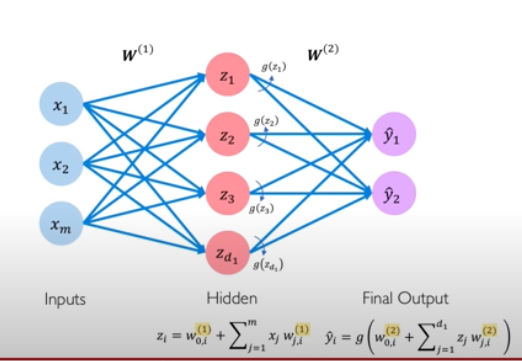
* Layered Neural Network: multi output perceptron이 모이고, 이들의 output에 한 번 더 과정을 적용한다면 위 그림과 같이 또 다른 층이 생겨난다. 이것이 바로 layered neural network, 층 신경망.

* Deep Neural Network : 위의 것을 여러번 반복하고, 다층의 구조가 생겨나게 되면 이것이 Deep Neural Network가 된다.
Gradient descent(경사하강법)
-
Loss function을 최소화 시키는 weight들의 값을 찾는 알고리즘. 수학에서의 최대, 최소값을 찾을 때 미분을 이용하는 것과 동치라 보면 된다.
- * 후에 추가.
Training in Practice - 실무에서의 학습법

neural network를 학습시키는 것은 어렵다. 위와 같이 Loss function vs weight의 그래프에서 볼 때 지역 minima가 많기 때문에 descent 알고리즘이 여기에 빠지기 쉽다.

또 learning rate n에 따라 실제 train 할 때에 능률에 큰 차이가 있다.

learning rate를 어떻게 설정하냐에 따라 loss function이 local minima에 갇힐 수도 있고, diverge할 수도 있다.
그래서 좋은 방법은 landscape에 적응할 수 있는 적응적 learning rate를 만드는 것이다.

SGD 외의 위와 같은 알고리즘들이 adaptive learning rate를 제공한다.
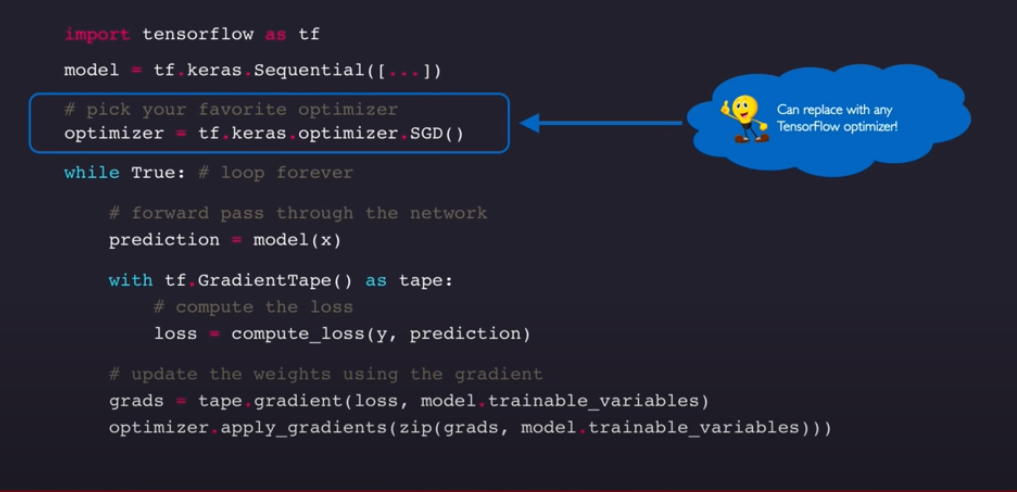
오늘 배운 것을 다 모아 구현한 것.
keras.Sequential이라는 wrapper를 통해 neural network를 만들고,
optimizer를 통해 gradient descent 알고리즘을 최적화하고,
loss function과 gradient계산 및 업데이트를 통해 최적의 w 값들을 찾는다.
*Mini Batches 소규모 배치들: Stochastic Gradient Descent
실무에서 모든 point에서의 gradient를 계산하는 것은 계산 비용이 너무 많이 들고, 너무 적은 point로는 noise가 크기 때문에, 적당한 사이즈의 computation인 mini batch를 이용한다.
Batch를 사용할 경우 parallel computation(병렬 연산)이 가능하여 GPU에서의 큰 성능 향상을 기대할 수 있다.
*Regularization 일반화 - To improve generalization of our model on unseen data ( 보지못한 데이터 셋에 대해 좋은 예측을 하기 위해)
1. Dropout: randomly set some activations to 0 during training뉴럴 네트워크의 어떤 activation에 대해 0으로 설정한다.
Typically drop 50% percent of activations in layer. It forces network to not rely on any 1 node.보통 50%의 activation을 드롭한다. 이것은 네트워크가 한 노드에 지나치게 의존하지 않게 한다.
tf.keras.layers.Dropout(p=0.5)
2. Early stopping : Stop training before overfitting
과적합(overfitting)이 오기 전에 학습을 멈추는 것이다. 아래 그래프와 같이 과적합이 오게 되면 training data에는 갈수록 loss가 줄어들게 되지만 testing data에는 loss가 증가되는 때가 생긴다. 이 때 학습을 멈추면 최적의 성능을 낼 수 있다.

참고: Alexander Amini, MIT 6.S191: Introduction to Deep Learning
www.youtube.com/watch?v=njKP3FqW3Sk&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI
'딥러닝' 카테고리의 다른 글
| Transfer Learning (전이학습) (0) | 2021.08.17 |
|---|---|
| Neural Network Implementation Flow in Tensorflow (0) | 2021.05.28 |
| CNN 기초 (0) | 2021.05.25 |